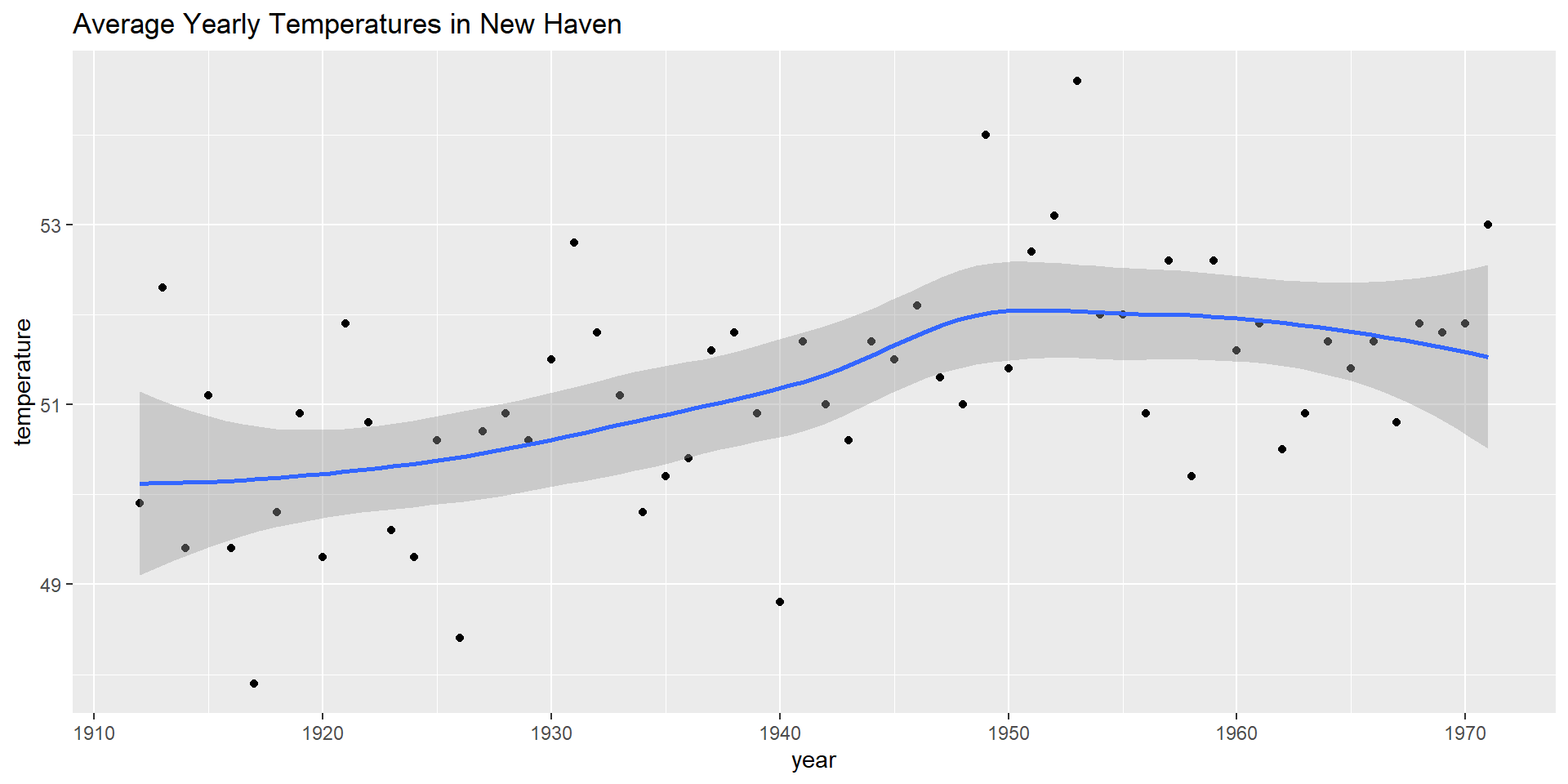
library(tidyverse) #nhtemp is built-in R tsdata.frame(year =as.numeric(time(nhtemp)), temperature =as.numeric(nhtemp)) |>ggplot(aes(year, temperature)) +geom_point() +# geom_smooth() +# plot smooth trend-curve (LOESS(small set)/lm (large set)) with a (default) 95% CIggtitle("Average Yearly Temperatures in New Haven")
Confidence intervals
\([0,1]\) is guaranteed to include \(p\), but not useful
the spread between -100% and 100%, will be ridiculed for stating the obvious.
Even a smaller interval, such as saying the spread between -10 and 10%, will not be considered serious.
a very small intervals but misses the mark most of the time will not be considered good
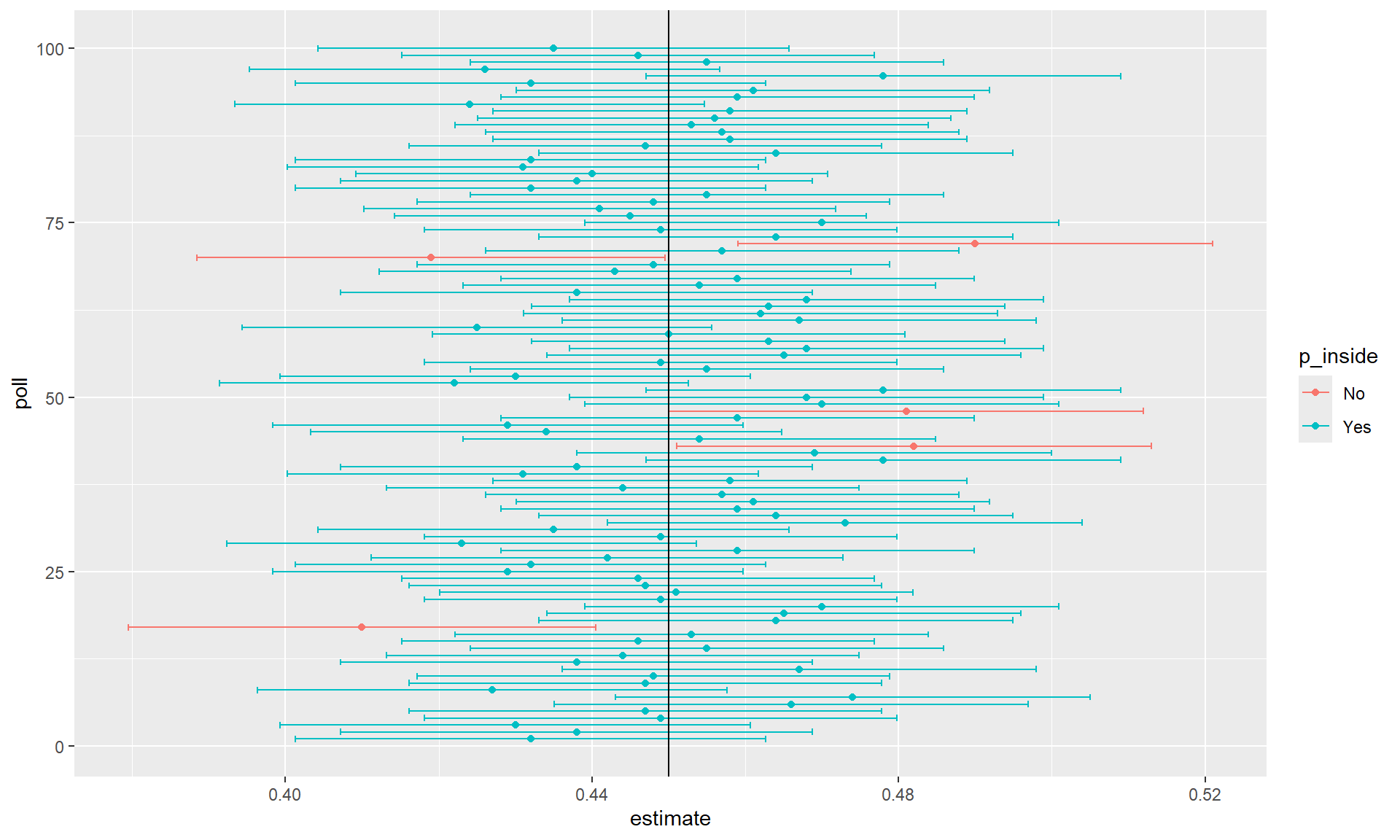
We can use the statistical theory to compute the probability of any given interval including \(p\).
Confidence intervals: MC simulation Parameter
To illustrate this we run the Monte Carlo simulation.
The term in the middle is an approximately normal random variable with expected value 0 and standard error 1, which we have been denoting with \(Z\), so we have:
\[
\mbox{Pr}\left(-1.96 \leq Z \leq 1.96\right)
\]
which we can quickly compute using :
pnorm(1.96) -pnorm(-1.96)
[1] 0.9500042
proving that we have a 95% probability.
Confidence intervals of 99% confidence level
If we want to have a larger probability, say 99%, we need to multiply by whatever z satisfies the following:
\[
\mbox{Pr}\left(-z \leq Z \leq z\right) = 0.99
\]