set.seed(1)
library(tidyverse)
library(dslabs)
take_poll(25) #dslabs function shows a random draw form thir urn
https://rafalab.dfci.harvard.edu/dsbook-part-2/inference/estimates-confidence-intervals.html
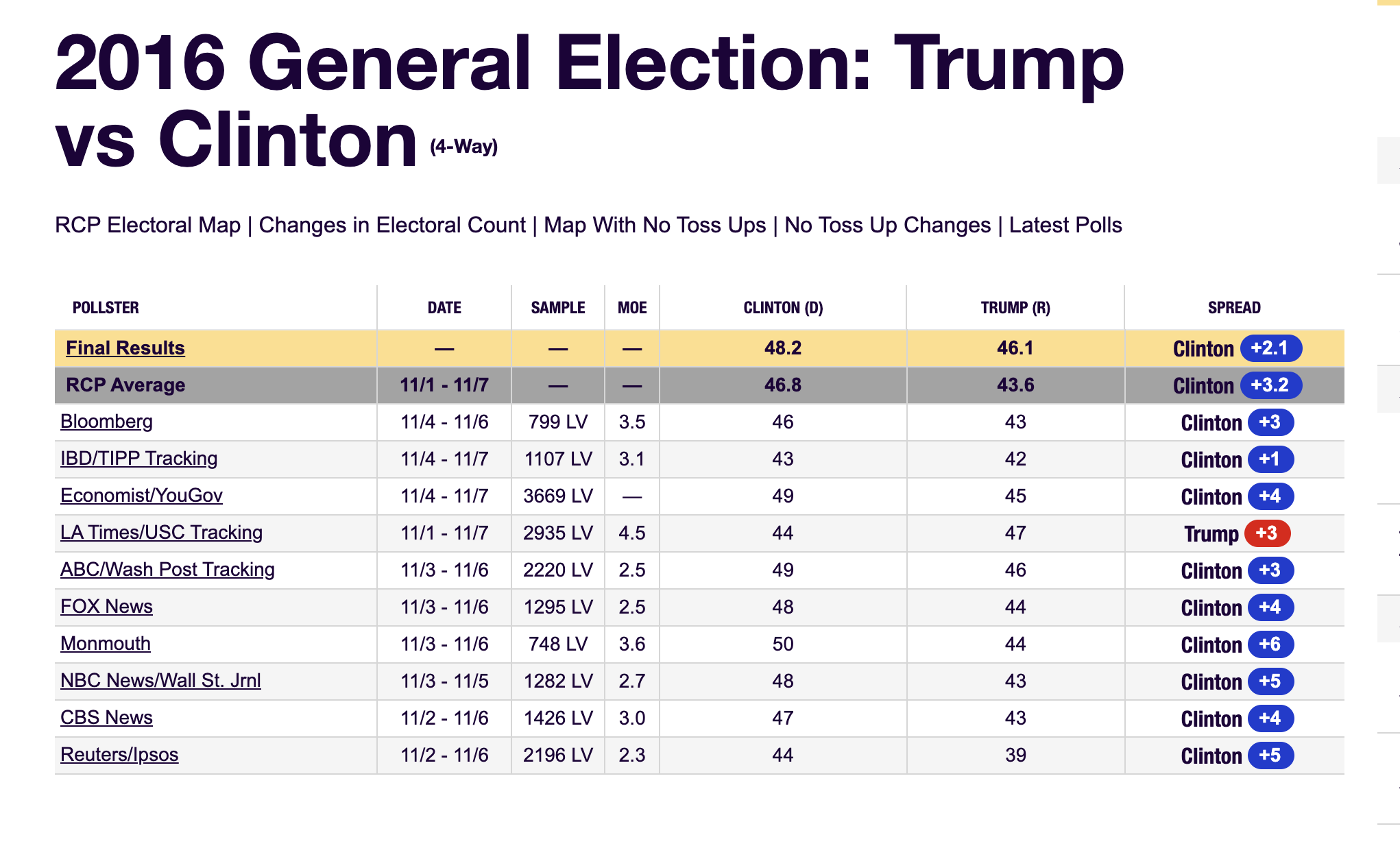
The week before the election Real Clear Politics showed this:
If the interval you submit contains the true proportion, you receive half what you paid and proceed to the second phase of the competition.
In the second phase, the entry with the smallest interval is selected as the winner.
par(mfrow = c(2,2), mar = c(3, 1, 3, 0), mgp = c(1.5, 0.5, 0))
take_poll(25); take_poll(25); take_poll(25); take_poll(25) 
par(): changes plotting layout and marginsmfrow=c(2,2): 2 by 2 gridmar=c(3,1,3,0): set margins in the order of c(bottom, left, top, right)mgp=c(1.5, o.5, 0): (postion of the axis title, axis tick labels, axis line)
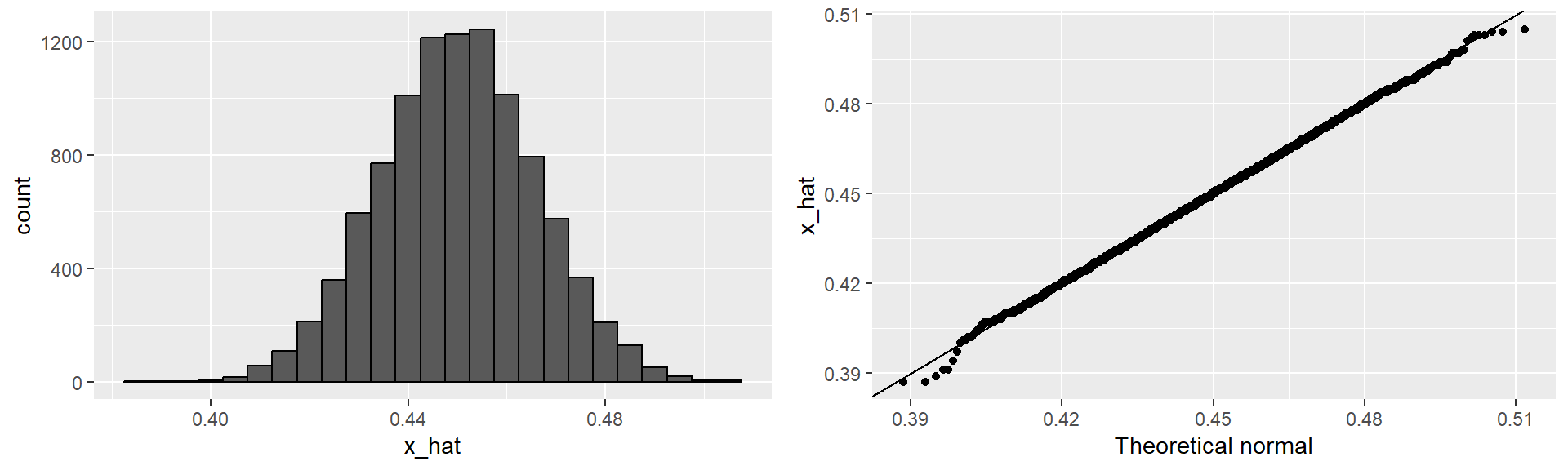
# cache=FALSE: tell Quarto not to cache the reuslts of this chunk
library(tidyverse)
library(gridExtra)
p1 <- data.frame(x_hat = x_hat) |>
ggplot(aes(x_hat)) +
geom_histogram(binwidth = 0.005, color = "black") #binwidth: refer to the data values
p2 <- data.frame(x_hat = x_hat) |>
ggplot(aes(sample = x_hat)) +
stat_qq(dparams = list(mean = mean(x_hat), sd = sd(x_hat))) + # compare to Normal(mean, sd), not Nornal(0,1)
geom_abline() + #geom_abline(intercept=0, slope=1)
ylab("x_hat") +
xlab("Theoretical normal")
grid.arrange(p1, p2, nrow = 1)