beads <- rep( c("red", "blue"), times = c(2,3))
#rep(x, times=...):repeat each element of x the number of times gieven in times
beads[1] "red" "red" "blue" "blue" "blue"https://rafalab.dfci.harvard.edu/dsbook-part-2/prob/discrete-probability.html
\[ \mbox{Pr}(A \cup B) = \mbox{Pr}(A) + \mbox{Pr}(B) - \mbox{Pr}(A \cap B) \]
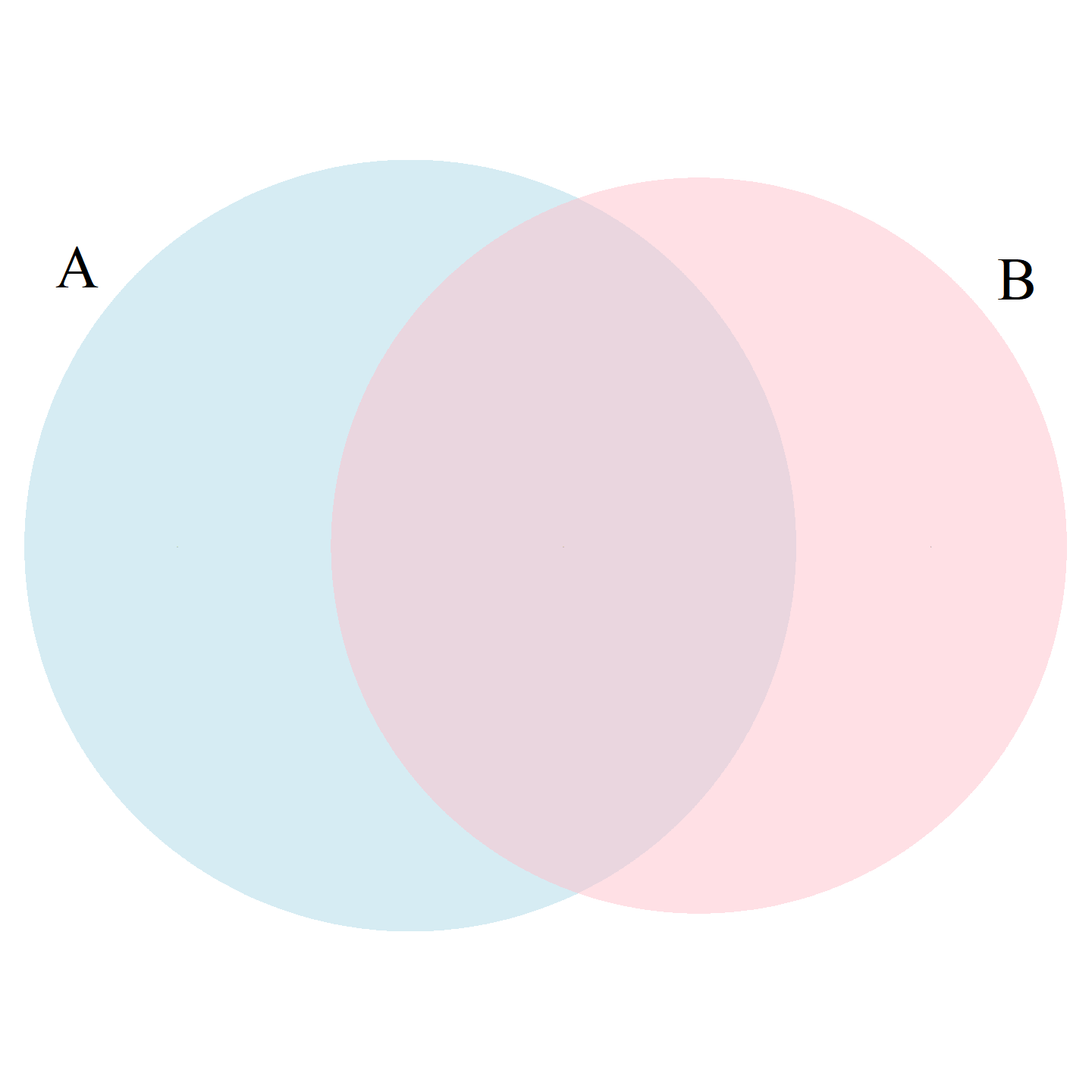
library(VennDiagram)
rafalib::mypar() # sets some base plotting parameters, relevant to base R plots
grid.newpage() # clears the curetn grid graphics page
tmp <- draw.pairwise.venn(22, 20, 11, category = c("A", "B"), #(areaA=22, areaB=20, coss.area=11)
lty = rep("blank", 2), # remove the circle borders
fill = c("light blue", "pink"),
alpha = rep(0.5, 2),
cat.dist = rep(0.025, 2), # distance of category lables from the circles
cex = 0, # tex size fore region counts. 0 hides the numbers
cat.cex = rep(2.5,2)) # text size for the category labels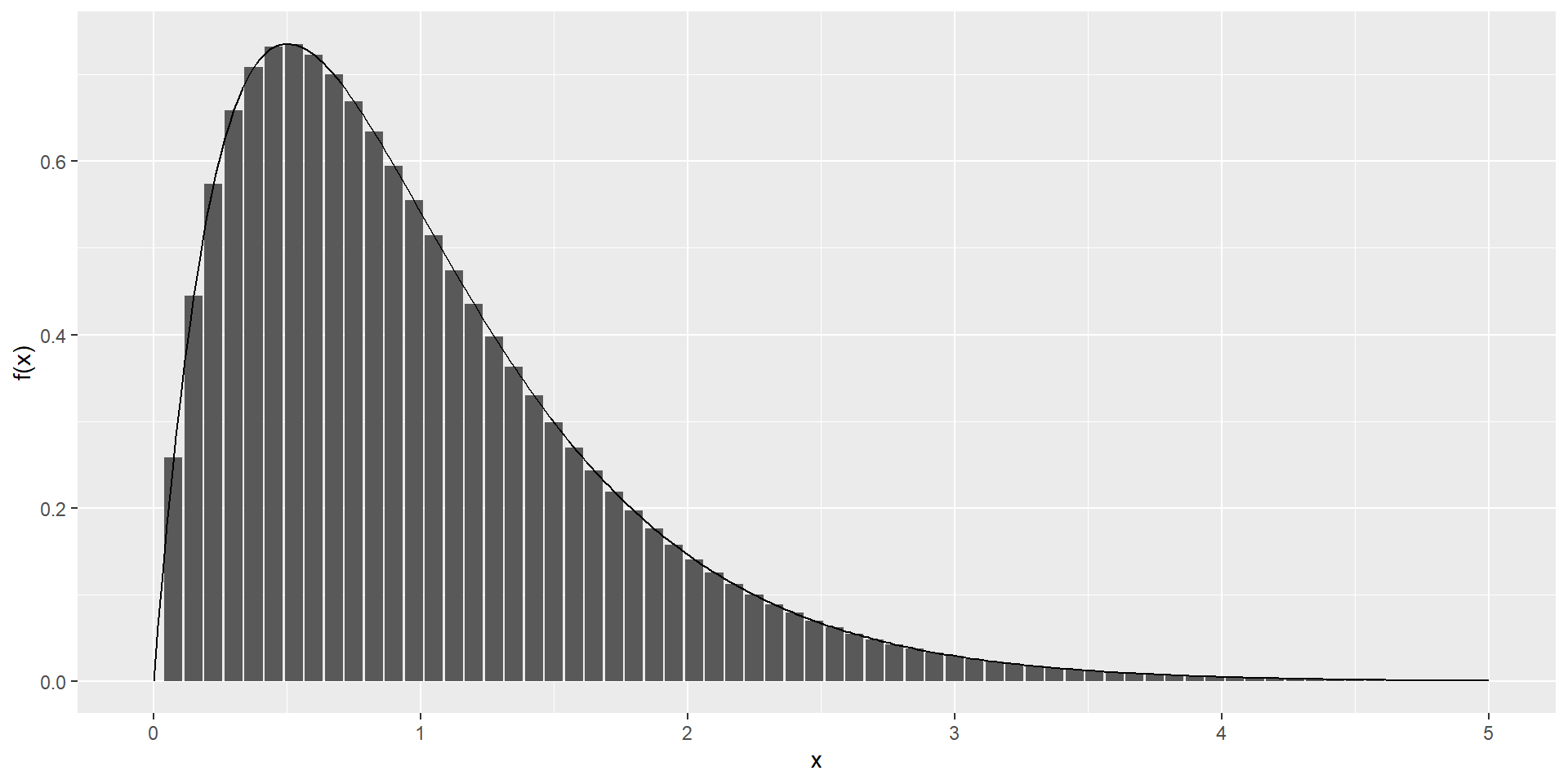
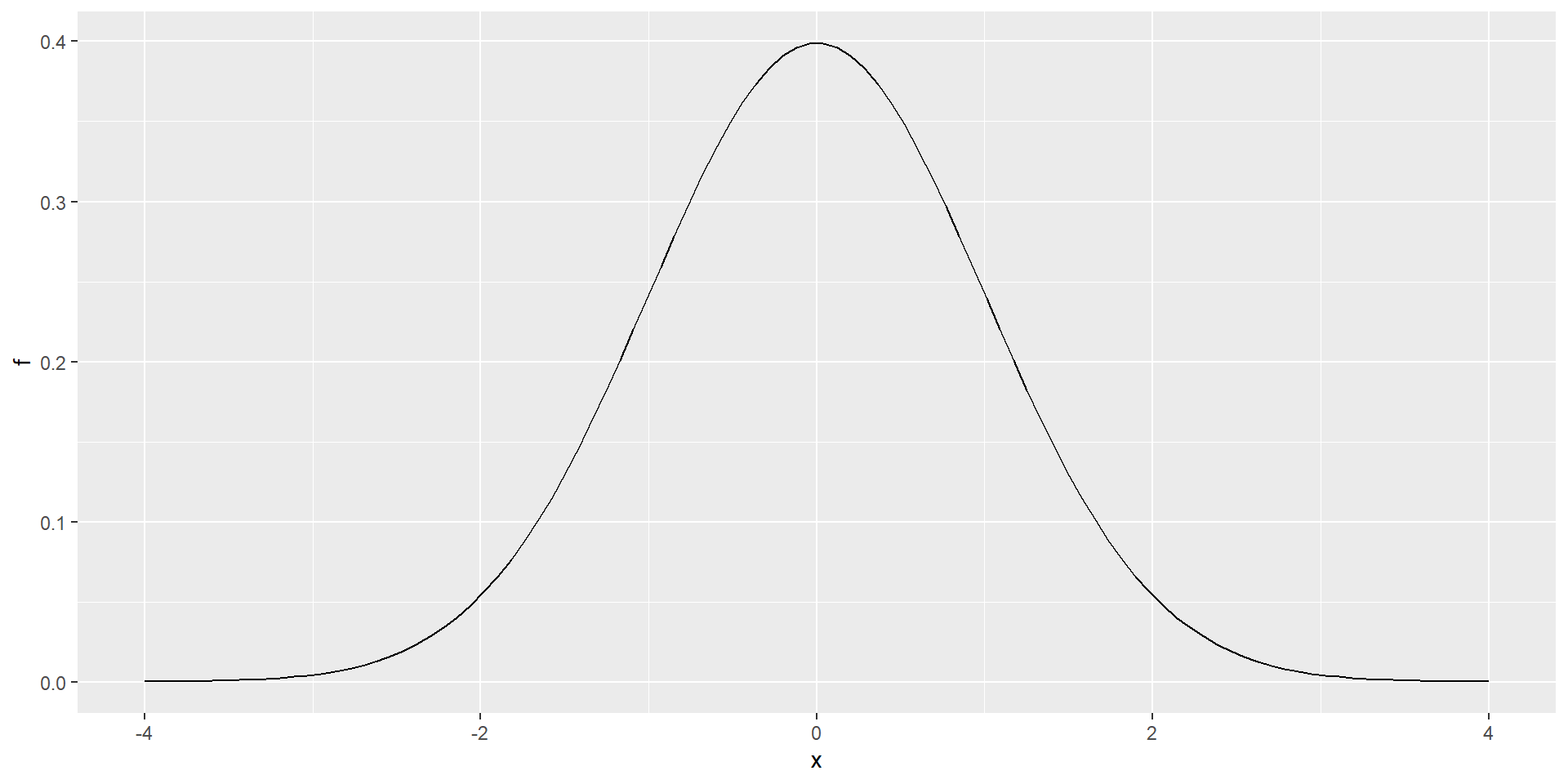
cont <- data.frame(x = seq(0, 5, len = 300), y = dgamma(seq(0, 5, len = 300), 2, 2)) #Gamma(shape=2, rate=2): f(a, b)=b^a/Gamma(a) x^{a-1}e^{-bx}
disc <- data.frame(x = seq(0, 5, 0.075), y = dgamma(seq(0, 5, 0.075), 2, 2))
ggplot(mapping = aes(x, y)) +
geom_col(data = disc) +
geom_line(data = cont) +
ylab("f(x)") 
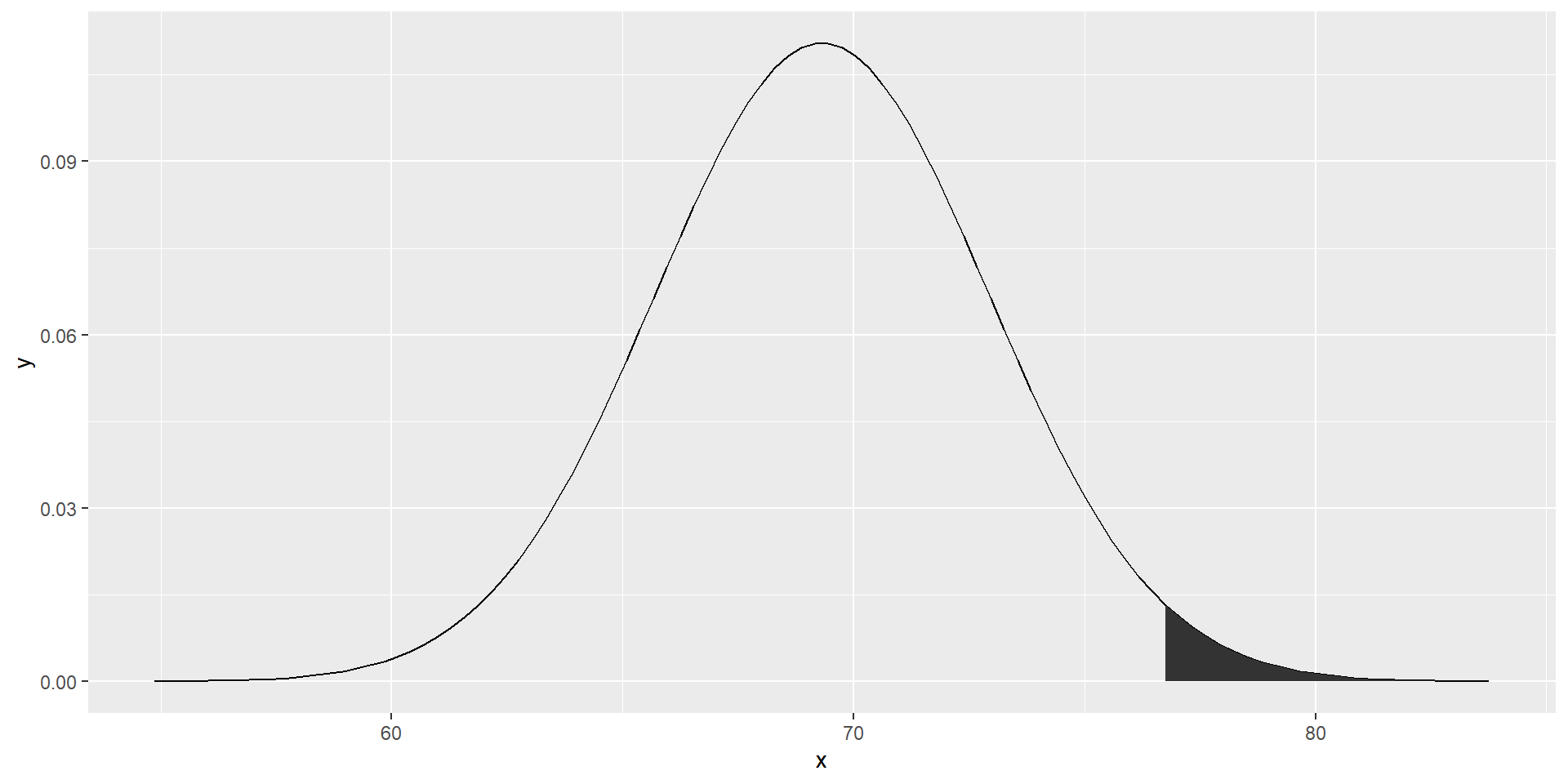
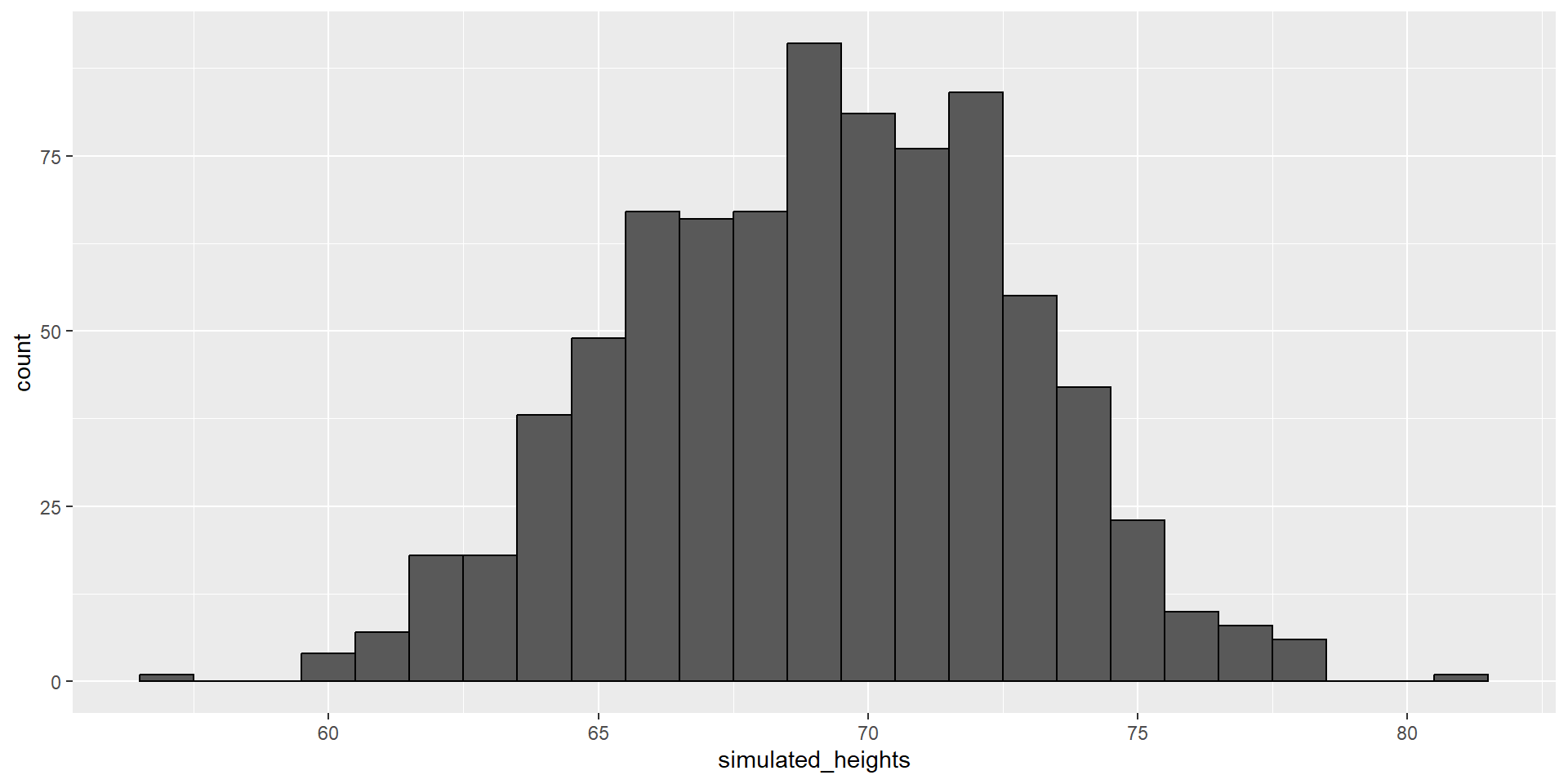
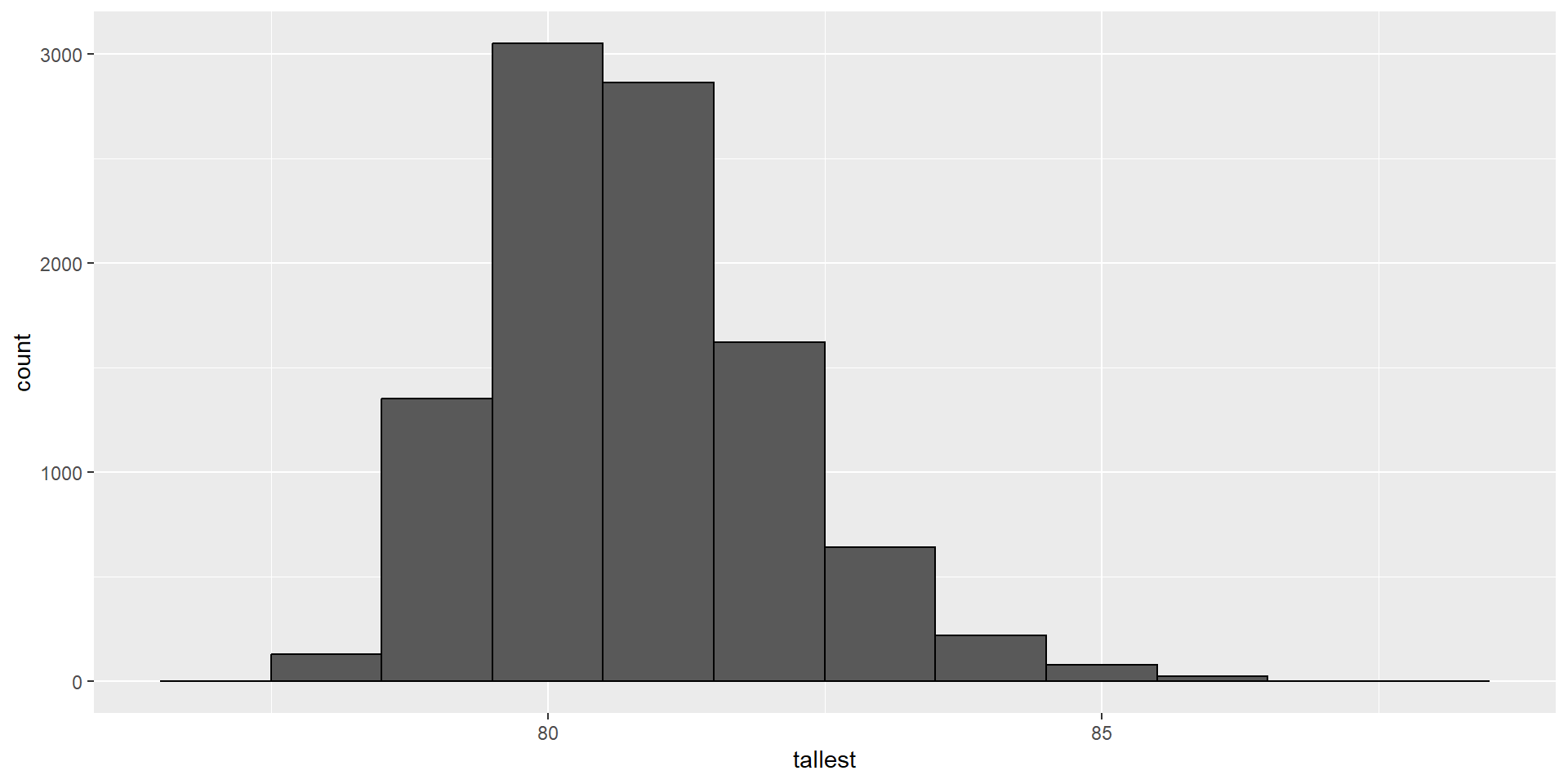
table(): frequency counts. Default drops NA, unless table(x, useNA="ifany")prop.table(): divides those counts by the total count->relative frequencyR uses the letters d, q, p, and r in front of a shorthand for the distribution.
We have already seen the functions dnorm, pnorm, and rnorm for the normal distribution.
The functions qnorm gives us the quantiles.